Prompt engineering involves organizing text so that a Generative AI Large Language Model (LLM) can interpret input and generate an expected or desired output.
Imagine a friend is making you a sandwich and you want them to prepare it just the way you like it. You say, “Hey, could you throw in some extra cheese and skip the tomatoes?” That’s a lot like how prompt engineering works. You are telling a LLM that feeds a voicebot how you want it to respond. By being very specific about what you want to want to hear (the right request), you’re one step closer to getting what you want (the best response) … or the best sandwich.
In a previous post, “AI + WebRTC Product Development: A Blueprint for Success”, we introduced you to Polybot.ai, an AI Translator bot that combines the power of Generative AI and LLMs with the real-time communication and media stream manipulation capabilities of WebRTC. Next, in “Developing a Brand Strategy and Identity for an AI-Powered WebRTC Application”, we led you through the branding process for Polly (as we like to call her), also powered by AI.
Watch a demo of our Polybot.ai Real-Time Translation Application!
Today, we are going to walk through choosing the right LLM and then expand upon how we designed the prompt engineering for Polly. We applied an iterative process to design, test, and improve the clear prompts for our translator bot in order for users to receive the answers we expect. Just like a quest for the perfect sandwich!
Choosing the right LLM for your project is a key action before creating prompts. It’s important to choose a model that aligns with the requirements of your particular use case and the parameters of your application.
Consider an LLM’s:
There are so many LLMs to choose from. For this proof of concept project, we used OpenAI’s GPT LLM. Our partner Symbl.ai also has an excellent LLM called Nebula.
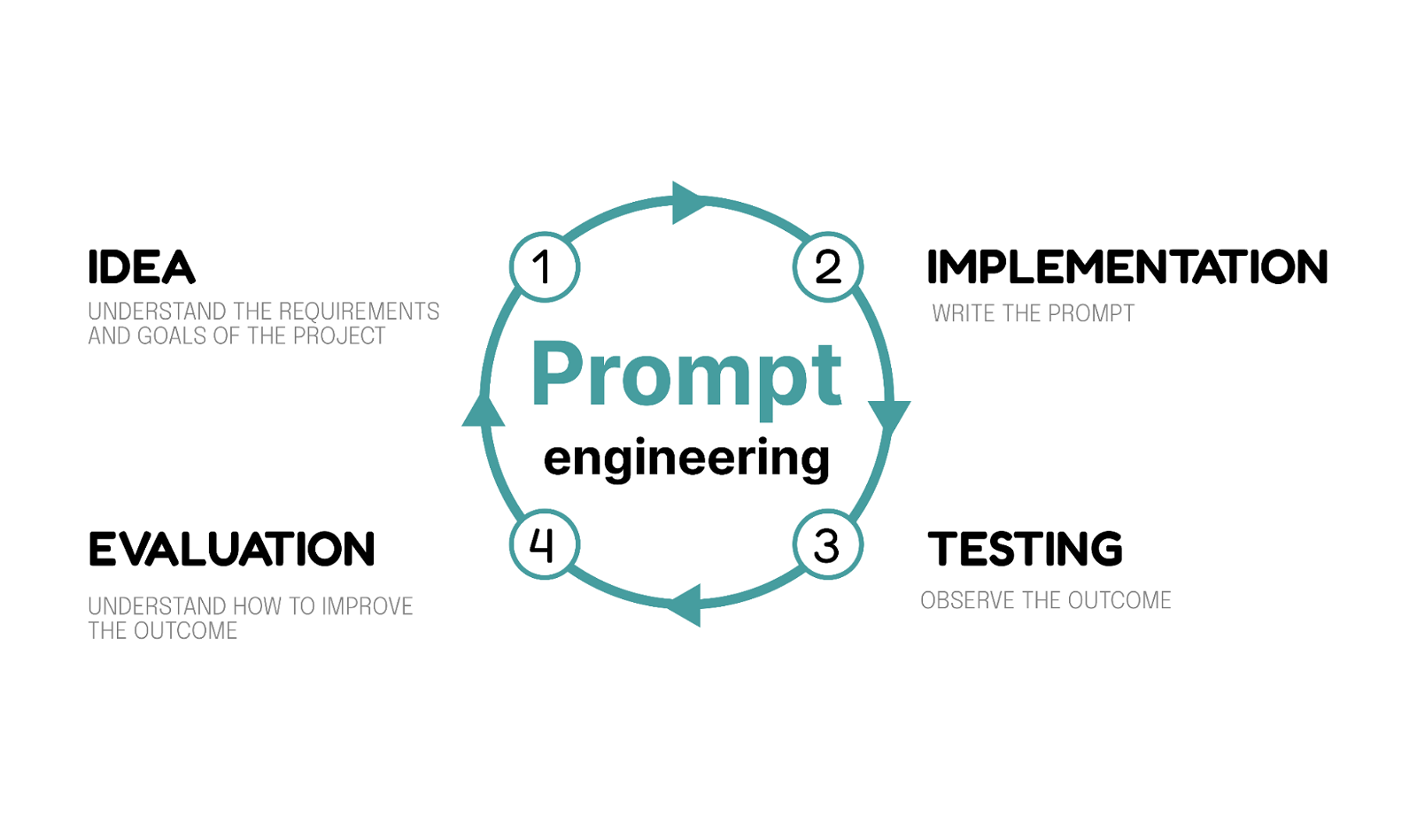
For this project, we implemented an iterative prompt generation cycle that included understanding the requirements and goals of the project, writing the prompts, testing it with our language model, understanding the outcome, and iteratively enhancing it for optimal performance.
Before starting to write any prompts, it’s very important to understand the context and goal of the project. For this application, we are facilitating communication by translating a conversation between two people who do not speak the same language. The interaction within the app must be very simple and straightforward.
To craft effective prompts that are designed to tap into the power of LLMs, consider the following:
1. Clearly Define the Task
Start by stating the basic instruction. Then modify the prompt until you get to the expected outcome.
2. Add Detailed Context and Instructions
Include specific actions about the desired outcome, format, style, etc.
For instance, if translating from language A to language B, specify the context, i.e., being on a live call with someone who doesn’t speak the same language, the language it should translate, and so forth.
3. Summarize Steps
List the key steps the model should follow to complete the task successfully. This helps prevent unintended actions and ensures that the model adheres to the desired process.
4. Incorporate Bot and User Personas
These enhance the user experience and help guide the model in generating responses that align with the intended behavior. A bot’s persona can include factors like its name, gender, job, back story, tone, and personality traits. As described in the branding post, our Bot is called Polly. Our user personas are business professionals, travelers, students, patients and anyone in need of quick, accurate translations.
5. Communication Flow Instructions
In order to facilitate smooth communication between users and the model, clearly outline steps to avoid disruptions and maintain a seamless interaction, fostering a positive user experience.
Prompt engineering does involve a good bit of trial and error. You must keep testing and checking the results. Ask yourself: Does the output match what you had in mind? If not, how can I change it to get the desired result?
For example, after multiple iterations, we came to a milestone and believed we had the definitive set of prompts that were telling the LLM what to do and providing the right context. The next step in the process was thorough testing.
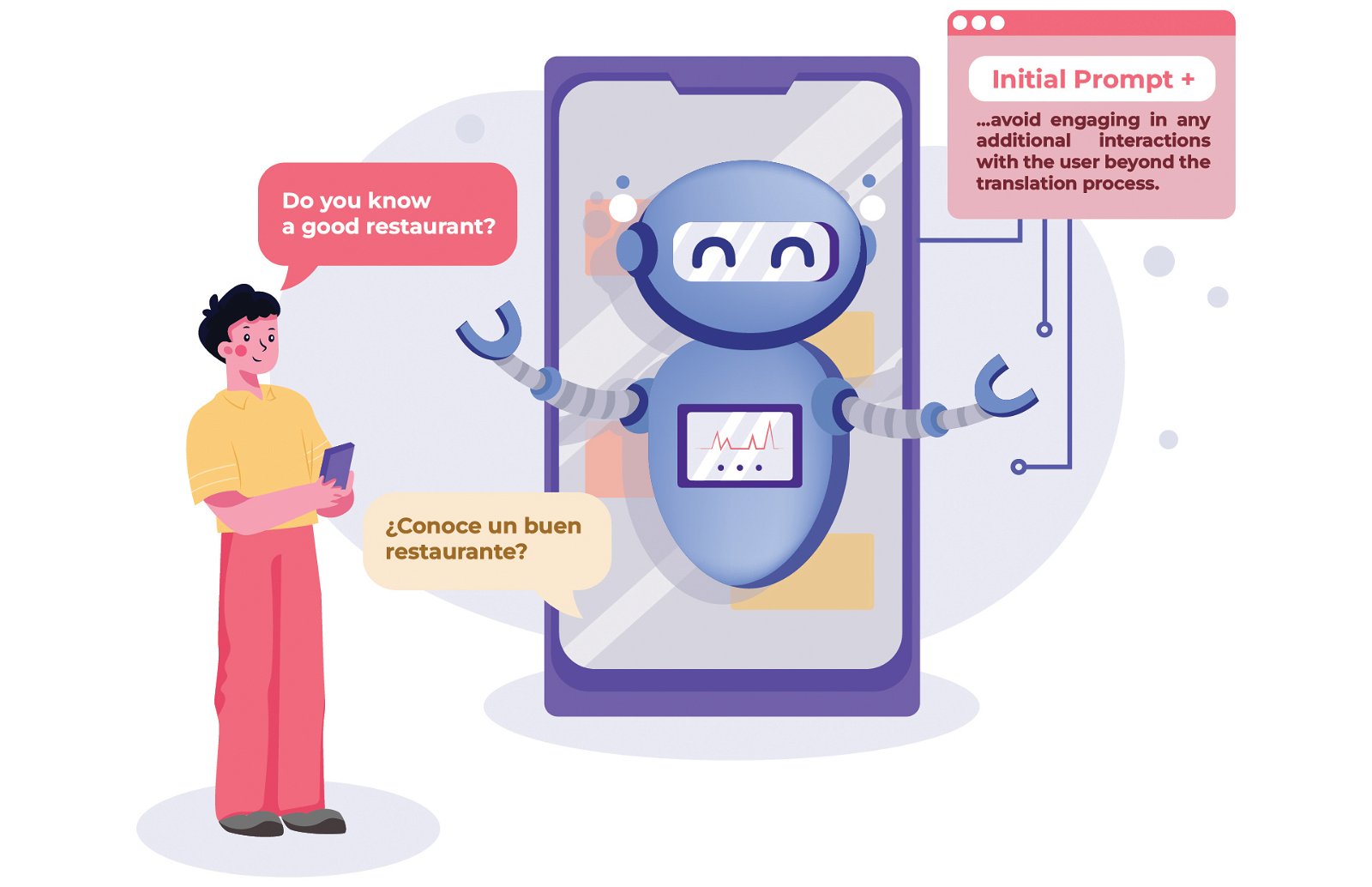
During this process, we found something unexpected: Polly started answering questions the users wanted translated! Polly translated, “Do you know a good restaurant in the area?” as per her instructions. But then she joined as an unexpected participant in the conversation. She followed up by asking, “Are you asking me to recommend you a good restaurant?”
The solution was to revisit our sandwich instructions and add the extra sauce. In this case, tell the LLM to avoid engaging in any additional interactions with the users beyond the translation process.
In addition to the iterative process, it is also important to keep up to date with advancements with LLM models and natural language processing techniques. This helps you keep your prompts game strong and adapt to the latest advancements.
Creating prompts for LLMs is a mix of creativity and precision, just like creating the perfect sandwich. By taking an iterative approach, you can continually refine and optimize your prompts based on the model’s responses to achieve continuous improvement. Quick iterations allow prompt engineers to test hypotheses, identify issues, and implement improvements rapidly.
An iterative approach is even particularly crucial when working on specific tasks or domains. You can start with a general prompt and iteratively tailor it to the nuances of your task. Fine-tuning the prompt based on the model’s responses helps align the language model’s output with your specific requirements.
At WebRTC.ventures, we’re not just building great real-time audio, video, and chat applications. We’re building smart ones. Through these endeavors, we’re continually honing skills in areas such as prompt engineering. Contact us today to unlock the potential of AI for your business!
Posts in this series:
{kind=link}
{kind=link}
{kind=link}